Why famous MMLU Failed in Evaluation
Why MMLU Falls Short in Evaluating Reasoning Power for Agentic AI Systems
AIGEN AIAI AGENTSDATA QUALITY
Munter.ai Engineering Team
5/14/20253 min read
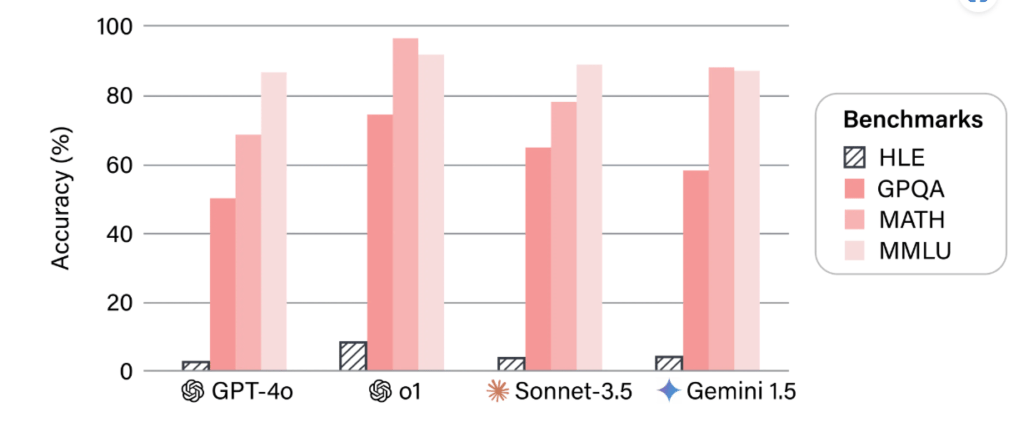
The Massive Multitask Language Understanding (MMLU) benchmark has long been a standard for measuring the general knowledge and academic proficiency of large language models. With its coverage of 57 subjects and thousands of multiple-choice questions, MMLU provides a wide-ranging assessment of factual recall and subject matter breadth. However, as agentic AI systems-autonomous agents that plan, reason, and act-become central to enterprise automation and decision-making, the limitations of MMLU as a reasoning benchmark are increasingly evident.
The Core Limitations of MMLU for Agentic AI Evaluation
1. Memorization Over Reasoning
MMLU’s format primarily rewards rote memorization and pattern matching. As a result, models can achieve high scores by leveraging their vast training data, rather than demonstrating genuine reasoning or adaptive problem-solving. This is a significant mismatch with the demands of agentic AI, where real-world tasks require multi-step reasoning and the ability to synthesize information across domains.
2. Lack of Real-World Complexity
Agentic AI systems operate in dynamic, unpredictable environments. They must interpret ambiguous inputs, make decisions with incomplete information, and adapt to new scenarios. MMLU’s static, decontextualized questions do not simulate these complexities, failing to measure an agent’s ability to handle the open-ended tasks typical in actual deployments.
3. Benchmark Saturation
Recent advances have led to top models consistently scoring above 90% on MMLU. For example, OpenAI’s latest models (o1, o3, o4-mini), Gemini 2.5 Pro, Grok 3 [Beta], Claude 3.5 Sonnet, and GPT-4.1 all achieve MMLU scores in the 90–92% range. As one industry report notes:
“Today’s leading models-OpenAI o1, o3, Gemini 2.5 Pro, Claude 3.5 Sonnet-consistently achieve MMLU scores above 90%. This benchmark has become saturated, making it difficult to distinguish true advances in reasoning or agentic capabilities.”
4. Poor Reflection of Agentic Reasoning
Despite these high MMLU scores, these same models often struggle with complex, multi-step agentic automation. As highlighted in the latest AI Index:
“Even as models surpass 90% on MMLU, they frequently underperform on benchmarks that require advanced reasoning, planning, and tool use-core skills for agentic systems. On more challenging benchmarks like Humanity’s Last Exam, top models score just 8–20%.”
5. Ambiguity and Quality Control
Some MMLU questions are ambiguous or poorly constructed, which can lead to misleading assessments. In contrast, real-world agentic tasks demand clarity, context awareness, and the ability to resolve ambiguity through reasoning.
Mitigating MMLU’s Evaluation Shortcomings
To address these limitations, the ability to evaluate a model directly for a specific downstream use case will be much more important. This requires:
a) Knowledge on how to efficiently and robustly evaluate LLMs: Teams need a deep understanding of evaluation methodologies tailored to their domain and use case.
b) The infrastructure to enable this: Organizations must invest in scalable, reliable infrastructure for continuous and context-aware evaluation.
c) Domain expertise to know how the problem can be modeled using an LLM: Subject matter experts are essential to design meaningful, relevant tasks that reflect real-world complexity.
Institutions will be less likely to share such evaluations, given that a release means they will become contaminated, reducing their usefulness. Benchmark creators should mitigate the risk of contamination in the design of their test data as much as possible. Internet data should be used sparingly-and not as the source of the solution. New benchmark data should ideally be created by humans from scratch. Here Munter.ai can come in picture to create benchmarking data for your domain and business case specific usecases.
The Need for Next-Generation Reasoning Benchmarks
For organizations deploying agentic AI, relying solely on MMLU can create a false sense of capability. Modern agentic systems require benchmarks that:
Test multi-step, adaptive reasoning and planning
Reflect real-world, open-ended, and dynamic scenarios
Assess tool use, collaboration, and interactive problem-solving
Emerging benchmarks like Humanity’s Last Exam and scenario-based evaluations are better suited to measure the reasoning power and practical readiness of agentic AI systems.
Munter.ai can assist companies building Agentic systems to understand context relevant evaluation matrics and create an evaluation strategy which is safe and secure.
Location
Vienna, Austria
Graz , Austria
Cochin, India
Contacts

Impressum
Privacy Policy
Terms & Conditions