Evaluating AI Agent Systems: Metrics and Best Practices for IT Service Companies
Metrics and Best Practices for IT Service Companies
AI AGENTSDATA QUALITY
Munter.ai Engineering team
10/12/20252 min read
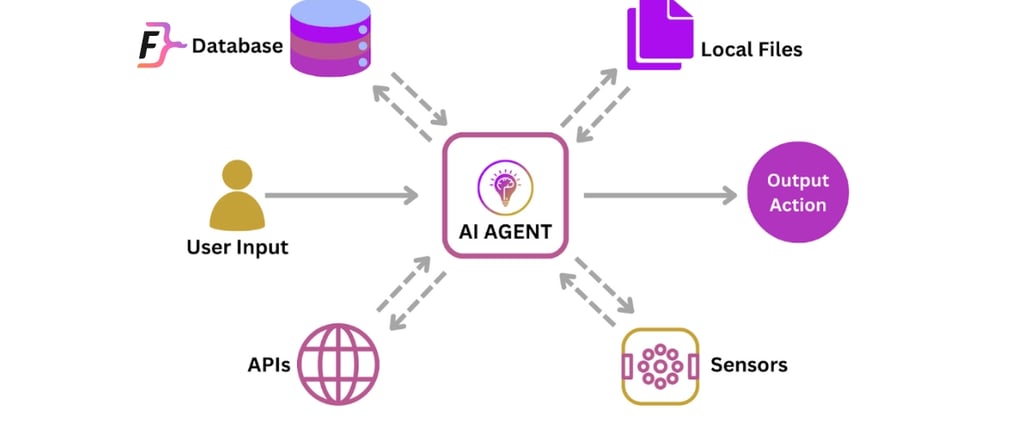
As AI agent systems become integral to automating workflows, enhancing customer experiences, and driving business insights, evaluating their performance comprehensively is critical. Evaluation spans multiple dimensions-from the quality of data these agents use, to the accuracy and relevance of their outputs, and the robustness of the underlying models and tooling. This article explores key evaluation metrics and strategies to help IT service companies ensure their AI agents deliver reliable, efficient, and ethical outcomes.
Evaluating the Data Used in AI Agent Systems
The data feeding AI agents forms the foundation of their capabilities. Evaluating this data involves:
Quality and Cleanliness: Data must be accurate, current, and free from noise or irrelevant content to avoid misleading the agent.
Coverage and Representativeness: The dataset should reflect the full diversity of real-world scenarios the agent will face, ensuring generalizability.
Bias and Fairness Audits: Identifying and mitigating biases in training and reference data prevents discriminatory or unfair agent behavior.
Compliance and Privacy: Data usage must align with regulatory requirements and organizational policies to ensure ethical AI deployment.
Thorough data evaluation reduces risks of poor agent performance and helps maintain trustworthiness.
Evaluating the Output and Response of AI Agent Systems
The core of AI agent evaluation is assessing how well the agent fulfills its intended tasks. Important metrics include:
Accuracy and Success Rate: Measures how often the agent achieves the correct or desired outcome.
Response Quality: For generative agents, this includes coherence, relevance, factual correctness, and conversational naturalness.
Latency and Efficiency: How quickly the agent responds or completes tasks affects user experience and operational cost.
Robustness: The agent’s ability to handle unexpected inputs, ambiguous queries, or adversarial conditions.
User Satisfaction: Human-in-the-loop evaluations, A/B testing, and surveys capture qualitative aspects like helpfulness, trust, and engagement.
Self-awareness of Failures: Whether the agent can recognize and communicate its own limitations or errors.
Combining automated evaluation tools with human feedback creates a balanced, scalable assessment framework.
Evaluating the Model and Tooling in AI Agent Systems
The underlying AI models and orchestration tools must be assessed for:
Task Adherence and Workflow Compliance: Ensuring the agent follows the intended multi-step processes without deviation.
Tool Usage Accuracy: For agents that call APIs or external services, correct and efficient tool invocation is critical.
Intent Resolution: The ability to correctly interpret and act on user goals.
Resource Utilization: Evaluating computational efficiency, cost-effectiveness, and scalability.
Security and Reliability: Resistance to attacks, failures, and unexpected inputs.
Observability and Traceability: Tools that provide insights into the agent’s decision-making paths help diagnose issues and improve transparency.
Building a Holistic Evaluation Framework
Effective AI agent evaluation combines:
Quantitative Benchmarks: Using standard datasets and metrics to measure accuracy, latency, cost, and robustness.
Human-Centered Evaluation: Incorporating subjective assessments of output quality, fairness, and user experience.
Component and Workflow Analysis: Testing individual modules and overall agent behavior for deeper insights.
Automated and Hybrid Approaches: Leveraging LLM-based judges and human reviewers to scale evaluation while maintaining nuance.
Conclusion
Evaluating AI agent systems requires a multi-faceted approach addressing data quality, output performance, and model/tool robustness. Munter.Ai can help you in implementing comprehensive, metric-driven evaluation frameworks for your AI agents.
Location
Vienna, Austria
Graz , Austria
Cochin, India
Contacts

Impressum
Privacy Policy
Terms & Conditions